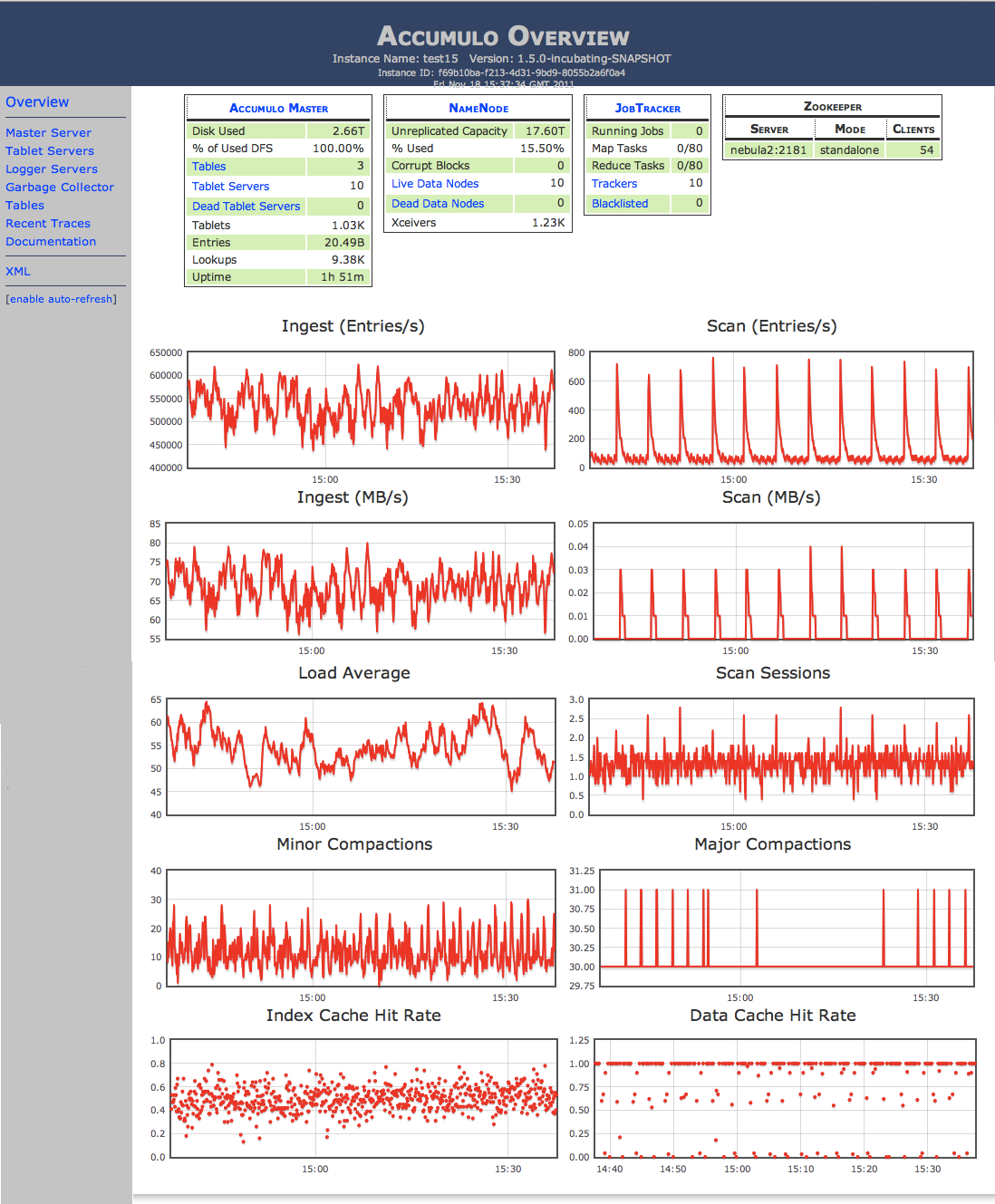
Software Screenshot:
Software Details:
Version: 0.8.2 / 0.9.0-rc0
Upload Date: 13 Apr 15
Developer: Apache Software Foundation
Distribution Type: Freeware
Downloads: 214
The Apache Whirr libraries are written in Java, with sprinkles of XML and Python.
They were written and compiled to provide a single-tool solution to work with the plethora of cloud services and cloud-based tools popping out everywhere on the Internet these days.
These libraries provide a common interface for interacting with each of these services/tools, automatically handling the differences between them.
Defaults for each service are provided and the developer only needs to make a few quick modifications to get an interface up and running withing minutes.
Features:
- Supported services:
- Most of the components of the Apache Hadoop stack
- Apache Mahout
- Chef
- Puppet
- Ganglia
- ElasticSearch
- Apache Cassandra
- Voldemort
- Hama
- Services can be deployed to:
- Amazon EC2
- Rackspace Cloud
What is new in this release:
- Adaptor for OpenStack Clouds
- Created Kerberos Service
- Added Python scripts to aid ssh/scp in to VMs
- Whirr script for Hadoop MRv2 YARN installs that supports Hadoop-2.0.x and Hadoop 3.x (trunk) branches
What is new in version 0.5.0:
- Sub-tasks:
- Support multiple versions of ZooKeeper
- Create ClusterSpec aware BlobStoreContext factory class
- Fixed Bugs:
- Log warning for unrecognized service names
- ZooKeeper service should only authorize ingress to ZooKeeper instances
- Whirr hangs when the file '$HOME/.ssh/known_hosts' includes an obsolete identifier for a certain ip address host.
- Improvements:
- Make more efficient use of ComputeServiceContext
- Add ClusterAction for generic script execution
- Improve error message if whirr.instance-templates left out of config
- Support multiple versions of Hadoop
- Update Configuration Guides with Recipe Info
- Clearly demarcate the user and service provider APIs
- New Features:
- [CDH] Start other services based on CDH, not just HDFS and MR
- Support local tarball upload
- Add Voldemort as a service
- Add ElasticSearch as a service
- Add support for BYON
What is new in version 0.4.0:
- Bugs:
- Instances should be started in the order specified in the template.
- [HBase] Integration test fails.
- Handle curl timeouts better.
- Log files should not be included in tarball or checked by RAT.
- CDH and Hadoop integration tests are failing.
- NPE for stopped instances on EC2.
- Resource functions/install_cdh_hadoop.sh not found when running from the CLI.
- Improvements:
- Users should be able to override an arbitrary Hadoop property before launch.
- Upgrade to jclouds 1.0-beta-9.
- Recipe for a HBase Cluster.
- Display available roles instead of service names when running ./bin/whirr.
- New Features:
- Allow users to log into clusters as themselves.
- Support user-defined images.
- Support locally-supplied scripts.
- Add the ability to destroy a cluster instance.
What is new in version 0.1.0:
- Sub-task:
- Fill in getting started documentation - getting-started.confluence
- Document and implement release process
- Add KEYS file to distribution directory
- Publish Maven artifacts to http://repository.apache.org
- Update quick start documentation to work with release 0.1.0
- Bug:
- hadoop-cloud push command invokes proxy creation
- Don't require manual installation of Apache RAT to compile
- Fix RAT warnings due to site files
- Cassandra POM should depend on top-level
- Workaround bug 331 in jclouds (Some EC2ComputeService operations fail for stopped instances)
- Only allow access to clusters from defined networks
- Hadoop service is broken
- Integration tests should not run on "mvn install"
- Log4j is missing from the CLI JAR
- Improvement:
- Create ant build for running EC2 unit tests
- Support additional security group option in hadoop-ec2 script
- Create setup.py for EC2 cloud scripts
- Generate RAT report
- Enforce source code style
- Separate unit and integration (system) tests
- Upgrade to jclouds 1.0-beta-6
- Allow script locations to be overridden
- Add Whirr quick start to README.txt and website (once it's live)
- Update POM to point to Apache RAT 0.8-SNAPSHOT
- Open up ports 50010 (JobTracker) and 50070 (NameNode) for the Hadoop Service
- Add core javadoc
- Create a Service factory
- Allow the Hadoop service to be run on Rackspace Cloud servers
- Adopt the standard Java SPI interface
- Implement service/cdh
- Introduce naming consistency for cloud service providers
- Unify ClusterSpec and ServiceSpec
- Decouple keypairs from the files that hold them
- Use Commons Configuration to manage cluster specs
- Clean up POM dependencies
- New Feature:
- Add support for EBS storage on EC2
- Run namenode and jobtracker on separate EC2 instances
- Write a Rackspace cloud provider
- Add a ZooKeeper service to the cloud scripts
- Add Cassandra service
- Add a CLI
- Task:
- Import initial source code from Hadoop contrib
- Import initial Java source code
- Create project website
- Add target directories to svn ignore
- Release version 0.1.0
Comments not found