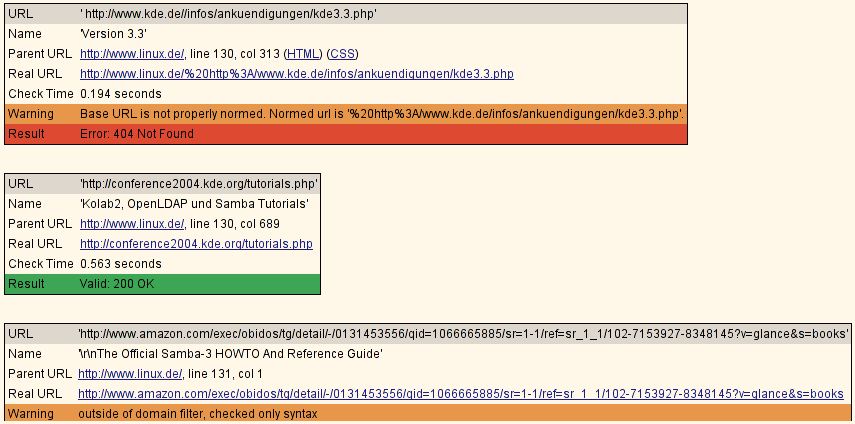
Software Screenshot:
Software Details:
Version: 9.3
Upload Date: 13 May 15
Developer: Bastian Kleineidam
Distribution Type: Freeware
Downloads: 16
It can be used as a maintenance system for personal or corporate websites.
Features:
- Recursive checking
- Multithreaded
- Output in colored or normal text, HTML, SQL, CSV, XML or a sitemap graph in different formats
- HTTP/1.1, HTTPS, FTP, mailto:, news:, nntp:, Gopher, Telnet and local file links support
- Restriction of link checking with regular expression filters for URLs
- Proxy support
- Username/password authorization for HTTP and FTP
- Robots.txt exclusion protocol support
- i18n support
- A command line interface
- A (Fast)CGI web interface (requires HTTP server)
What is new in this release:
- Features:
- Parse and check links in PDF files.
- Parse Refresh: and Content-Location: HTTP headers for URLs.
- Changes:
- PDF and Word checks are now parser plugins (PdfParser, WordParser). Both plugins are not enabled by default since they require third party modules.
- Print a warning for enabled plugins that could not import needed third party modules.
- Treat empty URLs as same as parent URL.
- Replaced the twill dependency with local code.
- Fixes:
- Catch XML parse errors in sitemap XML files and print them as warnings.
- Internal URL match pattern.
What is new in version 9.0:
- Supports connection and content check plugins.
- Move dlots of custom checks like Antivirus and syntax checks into plugins (see upgrading.txt for more info).
- Added options to limit the number of requests per second, allowed URL schemes and maximum file or download size.
What is new in version 8.2:
- Fixes:
- Anchor checking of cached HTTP URLs.
- Cookie path matching with empty paths.
- Handling of non-ASCII exceptions (regression in 8.1).
- Configuration directory creation on Windows systems.
What is new in version 7.9:
- Support RPM building with cx_Freeze.
- Added .desktop files for POSIX systems.
- Allow writing of a memory dump file to debug memory problems.
What is new in version 7.7:
- Detect invalid empty cookie values.
- Fixes cache key for URL connections on redirect.
- Made locale domain name lowercase, fixing the .mo-file
- Fixed CSV output with German locale.
- Writes correct statistics when saving results in the GUI.
What is new in version 7.5:
- Bug Fixes:
- Properly handle non-ASCII HTTP header values.
- Work around a Squid proxy bug which resulted in not detecting broken links.
- Fixed typo in the manual page.
What is new in version 7.2:
- Fixes:
- Checking: HTML parser now correctly detects character encoding for some sites.
- Logging: Fix SQL output.
- Checking: Fix W3C HTML checking by using the new soap12 output.
- Changes:
- Configuration: Parse logger and logging part names case insensitive.
- GUI: Add actions to find bookmark files to the edit menu.
- Features:
- Checking: If a warning regex is configured, multiple matches in the URL content are added as warnings.
- GUI: Allow configuration of a warning regex.
What is new in version 6.7:
- Fixes:
- Fix display of warnings in property pane.
- Don't forget to write statistics when saving result files.
- Added configuration file locations in HTML documentation.
- Removed mentioning of old -s option from man page.
- Only write configured output parts in CSV logger.
- Correctly encode CSV output.
- Don't print empty country information.
- Don't crash while handling internal error in non-main threads.
- Changes:
- Improved display of internal errors.
- Print more detailed locale information on internal errors.
- Features:
- Added CSV output type for results.
- Use Qt Macintosh widget style on OS X systems.
- Print recursion level in machine readable logger outputs xml, csv and sql. Allows filtering the output by recursion level.
What is new in version 6.5:
- Fixes:
- Checking: Fix typo calling get_temp_file() function. Closes: SF bug #3196917
- Checking: Prevent false positives when detecting the MIME type of certain archive files.
- Checking: Correct conversion between file URLs and encoded filenames. Fixes false errors when handling files with Unicode encodings.
- Checking: Work around a Python 2.7 regression in parsing certain URLs with paths starting with a digit.
- cmdline: Fix filename completion if path starts with ~
- CGI: Prevent encoding errors printing to sys.stdout using an encoding wrapper.
- Changes:
- Checking: Use HTTP GET requests to work around buggy IIS servers sending false positive status codes for HEAD requests.
- Checking: Strip leading and trailing whitespace from URLs and print a warning instead of having errors. Also all embedded whitespace is stripped from URLs given at the commandline or the GUI. Closes: SF bug #3196918
- Features:
- Configuration: Support reading GNOME and KDE proxy settings.
Requirements:
- Python 2.6 or higher
Comments not found