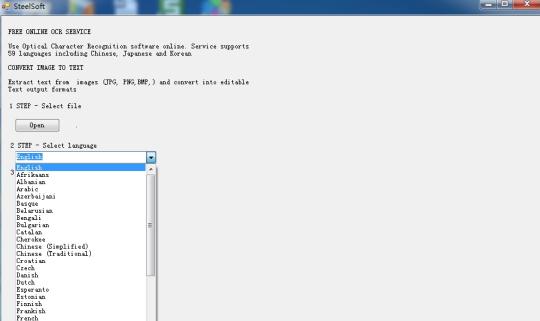
Recognize text from images using the Tesseract OCR Engine based on the cloud technology. Use Optical Character Recognition software online. Service supports 59 languages including Chinese, Japanese and Korean. Extract text from images (JPG, PNG,BMP,TIF) and convert into editable Text output formats.
It is based on cloud technology, and very famous OCR engine( Tesseract OCR Engine), so there is only hundreds of KB in size, but it can extract text in 59 languages, from the images. It supports more languages: Bulgarian, Catalan, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovene, Spanish, Swedish, Tagalog, Turkish, Ukrainian, Vietnamese etc.
What is new in this release:
Version 5.0 includes UE improvements.


Comments not found